Open for extension closed for modification. This means that our code is written in such a way that our class can have new behaviour without changing its structure.
Lets say that we have a Task and this task can have a description, a status and a couple of on/off characteristics like the fact that can be edited, shared or tracked.
Using flags
One way to depict this in code is by using flags in the form of booleans:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This means that every time we need to add a new characteristic we have to modify the Task class and add a new boolean property. This violates the open close principle making the code difficult to scale.
Using a list of enums
Another way is to replace all these flags with a list of enums:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Now if we need to add a new characteristic we simply add a new enum entry and the entire project can keep using the hasCharacteristic method to query a task for its characteristics.
Bonus benefit: this way we also avoid the wall of properties that sometimes hides information instead of revealing it!
Even though this acronym is quite catchy, SLAP is the one principle that you don’t find many people talking about.
Single Level of Abstraction
In essence, the principle proposes that each block of code should not mix what the code does with how it does it. Another way of thinking about it is, whenever possible, the code should describe in steps the actions that will take and then each step can elaborate on that.
For example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
this class has one method that showcases both what it does and how it does it.
If we want to SLAP it we need to delegate the how of each step to its own method:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
here the invoke method simply describes what will happen upon its invocation. A new task will be created, then saved and finally passed to any observers. For knowing how each step gets implemented we need to drill down one level. For example, creating a new task requires us to normalize the provided description and then create the task. For knowing how the normalization gets implemented we yet again move one level deeper!
Conclusion
Keep hiding how something gets implemented in new methods until you can no longer avoid it!
I want to be as explicit as possible and allow the reader of my code to have an uninterrupted flow.
Think about it. Every time you encounter the it keyword you do, a quick, conversion between what you see and what it represents. Personally I do it even in very small lambdas, imagine if you are two or three lines deep in a lambda and you see an it:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
It might not look much in this simple example but read it now with an explicit value:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
You don’t have to do a mental translation and it also provides some details regarding the format of username.
This last part can make the code even more readable since it allows us to describe the values we use:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Kotlin’s compiler is clever enough to figure out on its own what is the return type of a function but this does not mean that we should over use it and here is why:
Help the compiler to help us
By adding a return type in a function we instruct the compiler to expect and force that type (by a compiler error). On the other hand if we allow the compiler to infer the type, if something changes in the function’s body and the return type is not the one intended by the author, the compiler will follow along thinking that we know what we are doing!
Help the reader [to help us]
We write something once but it gets read multiple times. So it is our responsibility to make it as readable, explicit and quick in the eye as we can. In every case that we omit a return type the reader of our code has to do the calculations and extract the type on her own which, depending on the complexity, will take time and effort. You might say that a few seconds is not a big deal but in comparison with the zero seconds of having a type it is a lot.
Also not all reading takes place in an IDE that provides hints and colorful help. Our PR reviewers will probably read out code directly from GitHub or GitLab. By making them change context to figure something out we break their flow and concentration.
So, when should we use it
Never! In my humble opinion the only valid place is in small (one line), private methods that either construct something, so the use of the constructor along side the = sign trick the mind:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
A quick way to make a codebase more readable is to extract long or complex conditions / predicates to their own functions. The function’s name will explain to the reader what is being checked allowing her to move forward instead of trying to figure out the context or the calculations that are taking place.
The task
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Lets assume that we have a piece of code that prints all tasks that were created in the last two days and are, as the business experts calls them, completed. Which means that are either Resolved or Cancelled.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We have two distinct concepts that can be extracted. One that will explain the date calculations and one that will force the business knowledge behind those two statuses.
createdInTheLastTwoDays()
The calculations can be extracted to a private function but since we are using Kotlin we will extract them to an extension function to make the code even more readable:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Another benefit of having “the mentality of extraction” (yep, I just made it up) is that eventually we will come across a case like the completed which is a business term that has not been transferred to the codebase!
So we don’t just make the code more readable but we improve our domain representation and force a rule that until now was known through documentations or, even worse, through conversations only.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This is the one and only question that I ask myself when I see comments or when I feel that I need to write some:
Do these comments provide the reason why this code was written?
If not then 99.9% we don’t need them.
“Remove right margin”
I recently came across a block of code that looked like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
In this example the comment simply describes what the code does. I am pretty sure that everyone can figure that out but only the code’s author knows why we need to remove the margin under those circumstances. I am also sure that in six months (in my case in six days) even the author won’t remember the reason behind this code.
Extract if’s logic
To be fair I do understand the author’s urge to write this comment. Those unavoidable negations, because of the system’s/ui’s APIs, look like they need to be clarified.
Fortunately there is a better way to do that: we extract if’s logic to its own method and name it accordingly:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We can go a step further and extract if’s body to its own method too, having the code replacing the comment completely:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
So now what is missing is the reason behind the margin’s removal. A comment that answers the why and completes the reader’s understanding about the code she/he reads.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
And a good way to know if it doesn’t is to read it where it gets used. If, after reading it, you have questions then something is wrong with the name.
A good example is this code that I run into:
if (handleClickItem(customer)) {
return;
}
When I read this piece of code the very first thing that popped into my head was
How does the click gets handled?!
To figure that out I had to step into the function’s body and start reading it in order to understand what it does and when. It broke my flow and made me change context.
Turned out that this particular function, depending on the customer’s type, opens the contact’s screen and returns true or simply returns false. Having read something like:
if (openContactsScreenWhenCustomerIsCompany(customer)) {
return;
}
would have been enough for me to simply keep reading and never look back.
We have a task. A task can be unassigned OR it can be assigned either to a user OR a group.
First implementation: the ugly way
One way to implement this is by putting all the logic in the task:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
By default the task is unassigned and if we want an assigned task we provide a user or a group. The or factor is being enforced by a check in the constructor.
This
implementation not only relies on nulls to represent the business logic
but it also hides the logic from the developer who has to read the code
to understand how to create an assigned task.
The null checking comes also up when we want to figure out if and where a task is assigned which is tedious and can easily lead to bugs. As an example lets consider a simple function that prints the task’s assignment state:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Finally two points that we should not neglect are readability and scalability. When using UglyTask if we want our code to be readable, in all cases, we have to pass the arguments by their names (thank you Kotlin 🙂 ):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As far as scalability, consider how many changes we need to do to add a new assigned entity. One to the constructor, one to the init function to enforce our business logic and one in every function that we use the task’s state (see: printAssignment()) which adds even more null checks.
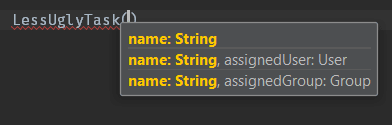
Second implementation: The less ugly way
Another way is by having multiple constructors, each for every valid assignment:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This implementation also puts all the logic in the task but it removes those null checks and makes it easier for the developer to understand it:
With that said, all other drawbacks in readability and scalability remain the same:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The best way to implement the business logic is by using Kotlin’s sealed classes. This way we can represent our business logic straight into our code and also keep our code clean, readable and scalable:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Now, printAssignment() leverages all of Kotlin’s powers, including smart cast, making it easier to the eye:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
and the rest of the code does not need any extra help like named arguments:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters