Disclaimer: this is not a paid post. I wrote it because I like the app and find it helpful. I also want to see, in a year, what has changed in the way I use it.
I always have a notebook next to my keyboard. I use it when trying to solve a bug or put in place a new feature. There was also a time that I used it to plan my day or keep notes for things that I wanted to ask or communicate. That didn’t last long since it wasn’t scaling!
That’s when I decided to move to a digital solution and search for the best to-do app. To be honest I can’t remember how I found out about Todoist. What I do remember though was that I did not check any other apps. Both its amazing human language parser and its shortcuts got me hooked immediately!
My usage
A little context. I use Todoist for over a year and only for work. That means that I don’t take advantage of their projects support. Every task gets added to the #Inbox which is my main driver. Throughout this year I’ve tried many setups and ways to incorporate my needs into the app. Here is how I use it:
Plan my day by setting the tasks that need completion
Every morning I see what needs to be done and create a task for it.
That does not mean that I open the company’s project management tool and copy whatever is assigned to me. I add only what cannot be tracked by the management tool. For instance, if a PR of mine got approved I add a task to merge my work in the main branch.
Also, if a meeting ends up with a couple of actionable items for me, I make sure to add them to Todoist. For example, talk to product about blah blah, comment on this thread, read that article, etc.
Another great source of action items is email. I go by them one by one and if something requires my attention I make a task for it.
Help me build habits
I try to cut down any distractions and one of them is looking at my emails every once in a while. What seems to work for me is to check them in the morning and create, if needed, tasks from them.
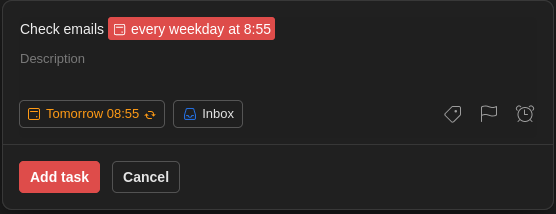
To force me in making it a habit I created a task that reminds me every weekday at 8:55 am to check my emails. This is 5 minutes earlier than when I start working so it gets registered, in my mind, as the first thing to do.
To show you the power of Todoist, for creating this task you need to write:
Check emails every weekday at 8:55
It will know what to do:
Reminders
Having a recurring task with a reminder is a good way to document things that do not belong anywhere else.
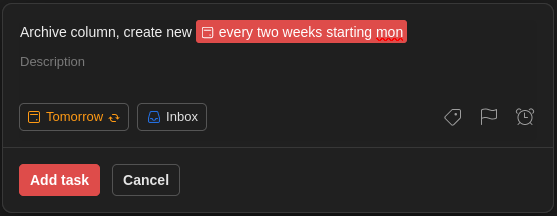
For example, every two weeks, on a Monday, I need to archive a column in our team’s board and create a new one.
Again, you can write it down
Archive column, create new every two weeks starting mon
and Todoist will understand it:
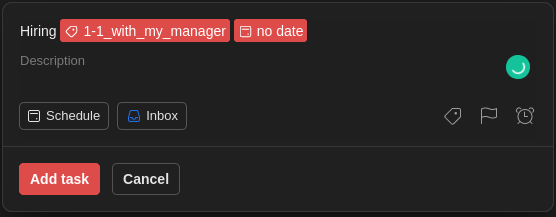
Write topics, questions, thoughts
Not everything is a task that needs completion. There will be topics and questions that must be communicated in a recurring meeting.
This is where I use labels for each meeting type and a task, with no date, for the topic/question.
This way, every time I am in one of these meetings, I open the label and have a list of what I wanted to discuss.
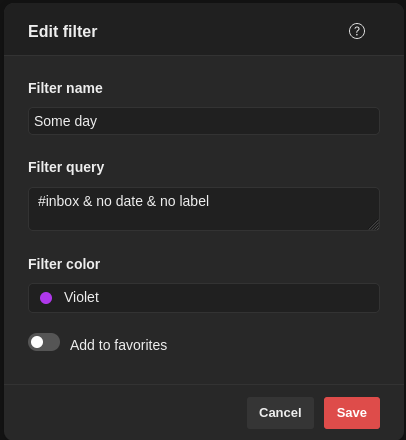
A task with no date and no label is also my way to write down my thoughts/ideas about the project. A possible refactoring, research for a new tool. Things that I need to get off my head but without setting a deadline.
Filters
I couldn’t close this post without mentioning filters. A feature that took me a while to use but can’t live without it anymore.
Better show you what I mean:
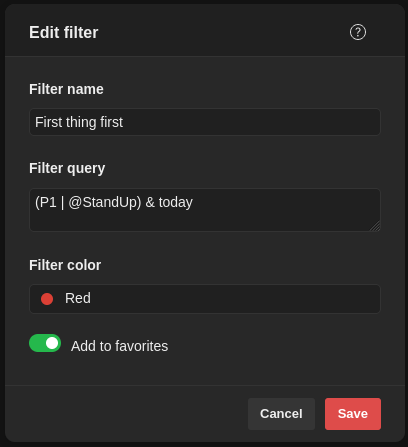
So, this is a filter I run every morning to see:
- today’s high-priority (P1) tasks or
- what needs discussion in the team’s stand-up
Another example is
that I use to resurface the thoughts and ideas that I mentioned before.