This is one of my favorite principles because it is easy to spot when violated and because it helps in having proper API surfaces when applied.
Tell, don’t ask
In essence this principle proposes that instead of asking from an instance for its values in order to decide how the same instance will execute something, just tell the instance to execute it. It knows its own state, it can make its own decisions!
Asking
By asking we actually refer to accessing many of a class’s properties. For example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
in the code above we ask the task to provide the values of three of its properties in order to decide if we are going to close it or not. In the process we (a) might had to expose those properties just for this code (creation date and subscribers could be private) and (b) inevitably leaked business logic that involves a task (when a task is eligible for closing).
Telling
Lets change the code in order to tell the task to close itself if possible:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I am under the impression that every time I come across a SOLID post, LSP and ISP are not given the same amount of attention as the other three. I guess its because they are the easiest to grasp but make no mistake, they are also the easiest to violate!
Liskov Substitution Principle (LSP)
In essence, LSP proposes that we create sub-classes that can be used wherever their parents are being used without breaking or changing the client’s behavior.
This means that in the code snippet below:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
we should be able to pass instances from all sub-classes of SoftwareEngineer without worrying that calculateSeniority will break or change the behavior of printSeniority.
Ways that we tend to violate LSP
By throwing an exception
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This is the obvious one. If, for example, the subclass adds a check that will eventually throw an exception then the client will break.
By returning undocumented results
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
In other words, the subclass returns something that the its parent never will. This forces the client to know about the subclass which makes the code less scalable.
By having side effects
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This is the subtle one since it does not change the client’s code but it does change the expected behavior. printSeniority is expected to make a calculation and then print the result but know it also makes a network call!
Interface Segregation Principle (ISP)
In essence, ISP proposes that interfaces should not play the role of “methods bucket” because eventually there will be a client that will not need to implement all of them.
This means that interfaces like this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
should break in more meaningful parts and allow every client to implement only the part that it needs:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Its worth mentioning that this way, in addition from avoiding ISP violation we also:
Keep our code from violating the SRP. In the first implementation, our cache depends in two things so it has more that one reasons to change (ex: a new parameter in the post method would force us to change our cache too)
Keep our code from violating the LSP. By having one interface, the first implementation of our cache couldn’t be used in code that expects repositories since its API methods would break the client.
Keep our code clean and scalable (the cache does not have to know about talking to the API)
Ways that we tend to violate ISP
Although there is not much to say here, since the only way to do it is by creating those buckets we mentioned above, beware of the creation since it comes in two flavors. The first is by having all methods in one file. Easy to catch it in a PR review. The second though is by having an hierarchy in our interfaces.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Primitive obsession is a known code smell that describes the usage of primitives for representing domain values. For example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
In this class both the user’s name and age are being represented by a string and an int respectively.
How else could we represent a name and an age? Well, the primitives are the correct ones but not for direct usage. We can build value objects upon them and encapsulate both the meaning of the value and the business logic:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
So what? You just wrapped a primitive and moved the check. True but now we have:
1. A reusable object
When the time comes and we need to have a new named entity we just use the class above and we can be sure that the business logic will follow along and be concise in the entire project.
2. Always valid instances
Whenever we see an instance of name or age we are certain that the instance holds a valid value. This means that an entity that consists from those value objects can only create valid instances and this means that the code that uses those entities (and value objects) does not need to have unnecessary checks. Cleaner code.
3. Code that scales more easily
Lets say that our business logic changes and we need to support users with invalid names too but without the need to deal with the name itself. Having a value object can help implement the change easily. We just change the Name class. All other code remains the same:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Lets say that our entities have the notion of an id and that after a few years the underline value needs to change from an integer to a long. By having a value object to represent the Id all changes will take place in the outer layers of our architecture where we load/fetch ids from databases/network and create the id instances. The rest of project will remain untouched, especially the domain layer that holds our business logic. If we had chosen the path of having an integer property in every entity then all of our entities, and the code that uses them, would need to change too.
5. Code that is more readable and reveals its usage
I’ve written a couple of posts in the past that showcase both the readability aspect and the revelation one.
6. A blueprint of our domain
When we open our project and see files like Invoice, Price, Quantity, Amount, Currency we get an immediate feel of what this project/package deals with and what are its building blocks. We consume information that we would otherwise need to dig inside each file to find out.
7. A context
The final and most important part of having value objects is that now we can complete our entities and build a context for our domain. A common language that we can use to communicate with other engineers and stake holders in general. Primitives are essential and they are the building blocks of a language but not of our business. The rest of company does not build its workflows upon integers and strings. It uses the businesses’ building blocks like age, name etc. It is vital that we do the same too in order to keep our code base in sync with the business.
This is the one principle that, chances are, you have applied even if you didn’t do it on purpose. In essence, if you have written code that does not have any control over the execution flow, then you most probably have applied the IoC principle. How?
IoC through design patterns
If you have implemented the strategy or the template pattern then you have applied the IoC principle. For example, having a report generator and feeding it with the necessary filtering code. All the code you write for filtering data, does not have any control over the execution’s flow. The generator is the one that decides when and if it will be invoked:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
The same goes with the template pattern too. The code you write in the template’s hooks is being controlled by the template and you don’t get to control it:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Both of these examples might seem weird since we are the ones that wrote both the filtering code and the generator so we feel that we control the flow. The thing is that we need to separate them in our heads and observe them individually. The generator is the one that controls the flow and dictates the actions that will take place. The filtering code is one of the actions. We just write them, provide them to the generator and that’s it.
IoC through frameworks
Another way of applying IoC is by using frameworks that have adopted it. Most popular are the IoC containers that are used to inject dependencies. Another example is the android’s framework. In android you don’t have control over an activity’s lifecycle and you simply extend the Activity class and override hooks to run your code.
IoC vs DI
Because of the aforementioned IoC containers, many people assume that dependency injection and IoC are the same. They are not. DI is just a way to help in applying the IoC principle. For example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
we can change the generator and have the filtering code being injected to it by constructor. The inversion is already happening, DI is simply used to provide the extra code.
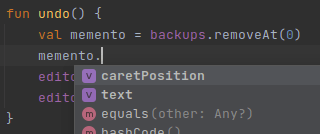
I started playing with the memento pattern for a use case I was researching when I realized that the Kotlin implementation had a, potentially, show stopper in comparison with the Java one:
I could not use a private property from within the same file
Why was that a show stopper? We’ll see, but first, what is the memento pattern?
Memento pattern
This pattern is a good way to implement a functionality that helps in restoring previous states. One good example is the undo in our text editors. You can write, edit, delete and then, by hitting undo, take each action back.
There are three main ingredients for this pattern:
the originator that holds the current state and creates snapshots of itself,
the memento that, in essence, is the snapshot with perhaps some additional metadata and
the caretaker that orchestrates the backup/restore of the state
So in our example the originator is the editor which knows what the text is, the carets position etc, the memento a copy of those values and the caretaker can be the interface between the user and the editor.
Java implementation
Lets try to have an overly simplified version of the above example in Java:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Here the editor, besides manipulating text, is able to produce snapshots of its state in a way that only itself can access the state’s values. The Memento class might be public, in order to allow the caretaker to handle instances of it, but its fields are private and only the originator can read them. A great way to copy something while having the smallest possible API surface and maximum privacy.
As a matter of fact, here is the caretaker and its usage:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As you can see the UI uses the editor to write, edit, delete but before that it saves a backup with the editor’s state in order to restore it every time the user hits undo!
Kotlin implementation
So lets move originator and memento to Kotlin. Ctrl+Alt+Shift+K and boom.. we have a problem:
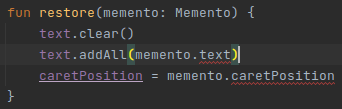
Kotlin, in contrast with Java, does not allow accessing private properties when in the same file.
What do we do? Well we can always make the properties public:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
but this way we, indirectly, expose the editors state:
Another way to implement the pattern is to have Memento as an interface with no state for the public API and have a private implementation of it for internal usage:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
this way we do not expose any state but we do open a bit our API. We now have an interface that can be implemented and given to the restore() function.
Inner classes
Fortunately Kotlin has inner classes. An inner class can access the outer class’s members but, most importantly, can be extended only from within the outer class. This means that this:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
While testing we tend to replace some of the unit’s collaborators with mocks as it is accustomed to call them. The problem with that name is that it is not accurate. The real name of those mocks is test doubles and there are four of them with mock being one of the types.
One reason for this misnaming is the wide usage of mocking frameworks that do not separate the types between them (I am looking at you mockito).
So, lets try to define the four types and see when it is best to use them. We will be using a made up browser and its history and will not use any framework. Just theory:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
A dummy is the test double that we use whenever we know that the collaborator will not be used:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
For example in the tests above we just need to check the browser’s active URL. We know that this does not evolve the browser’s history so we pass a collaborator that does nothing on every method call.
Stubs
A stub is the test double that we use whenever the collaborator is being used to query values:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
For example in the test above we feed the browser with a pre-populated history since we know that the browser will need to peek for the last visited URL.
Mocks
A mock is the test double that we use whenever the collaborator is being used to perform an action:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
For example in the test above we need to make sure that the browser saves the provided URL to its history so we use a collaborator that can verify this behavior.
Fakes
A fake is the test double that we use whenever we need the collaborator to provide us a usable business logic:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
For example in the test above we need a history instance that works as expected (a simple stack) but without the hassle of having a database or using the file system.
Final thoughts
Having your own test doubles per case makes the code simpler and more readable but does that mean that we should remove our mocking frameworks? In my opinion no. Having a framework saves you a lot of time and keeps things consistent, especially in big projects with lots of developers.
Knowing the theory behind something is always good since it lays a common foundation for discussions and decisions. A mix of the two, framework and theory, could be achieved and help the test code in readability. For example, we can keep using Mockito’s mock but name the variable stubBlahBlah if is used as a stub. This way the reader will know what to expect.
PS #1: Spock testing framework, besides being a great tool, provides a way to separate stubs from mocks not just in semantics but in usage too (ex: you cannot verify something when using a stub)
PS #2: There is another type of test double called Spy which is a toned down mock that helps in keeping state when a certain behavior takes place but does not verify it.
Even though this acronym is quite catchy, SLAP is the one principle that you don’t find many people talking about.
Single Level of Abstraction
In essence, the principle proposes that each block of code should not mix what the code does with how it does it. Another way of thinking about it is, whenever possible, the code should describe in steps the actions that will take and then each step can elaborate on that.
For example:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
this class has one method that showcases both what it does and how it does it.
If we want to SLAP it we need to delegate the how of each step to its own method:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
here the invoke method simply describes what will happen upon its invocation. A new task will be created, then saved and finally passed to any observers. For knowing how each step gets implemented we need to drill down one level. For example, creating a new task requires us to normalize the provided description and then create the task. For knowing how the normalization gets implemented we yet again move one level deeper!
Conclusion
Keep hiding how something gets implemented in new methods until you can no longer avoid it!
I want to be as explicit as possible and allow the reader of my code to have an uninterrupted flow.
Think about it. Every time you encounter the it keyword you do, a quick, conversion between what you see and what it represents. Personally I do it even in very small lambdas, imagine if you are two or three lines deep in a lambda and you see an it:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
It might not look much in this simple example but read it now with an explicit value:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
You don’t have to do a mental translation and it also provides some details regarding the format of username.
This last part can make the code even more readable since it allows us to describe the values we use:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Building upon my previous post and the trick of being specific in the values the code respects, one pattern that I’ve noticed which can easily lead in many false positive tests is sharing a constant value between production and test code.
If the test code reads the value from the production, any change that was done by mistake will not affect the test which will continue to pass!
21 yeas of age
Lets say that we have two services, one checks if a customer can enter a casino and the other if she can buy alcohol. For both cases the law states that the minimum legal age is 21 years old.
The code has a configuration file, a domain and two modules for each service:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As you can see the tests consume the minimum age directly from the production code but the test suite passes, life is good.
Then one day, the law changes and the minimum legal age for entering a casino drops to 20 years! Simple change, not much of a challenge for the old timers so the task is being given to the new teammate who does not know all modules yet and is also a junior software engineer. She sees the test, changes the value in the name to 20, sees the config, changes the constant’s value to 20, runs the test suite, everything passes, life is good! Only that it isn’t because the casino’s software now allows selling alcohol to 20 year olds!
Keep them separate
If the test code did not use the production’s code
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
then, after changing the constant’s value, the test suite would fail alerting the software engineer that something has broken forcing her to figure it out and craft another solution.
Tests help as make sure that our code works, provide us a safety net when we need to refactor and, when having proper test names, can be a good documentation describing what the code does. The last one can be especially helpful for both newcomers that need to understand the system and old timers that haven’t visited the code for a while!
A couple of tricks for achieving good names are:
Avoid describing how the code does something and try to describe what it does For example: calling add(item) results in calling recalculate is way too specific without providing anything meaningful, or anything that we wouldn’t get from reading the code. On the other hand: a recalculation of the order's value takes place every time a new item gets added shares an important information about the Order‘s behavior when adding an item.
Avoid being too abstract For example: a customer can buy alcohol when she is of legal age can help the reader understand how the code behaves but in a documentation you need specific values. So: a customer can buy alcohol when she is older than 21 years of age is much better because it also provides the exact threshold that our code considers for allowing someone to buy alcohol